Blog posts tagged golang
Asserting claims: Cryptographically signing the digital artifacts we produce

Why is SFO Museum signing the vector embeddings that we’re producing? To provide an additional guarantee that the data we are publishing is, in fact, the data we published. Vector embeddings are, by their nature, basically impossible to “spot check”. Their size, shape and volume lend themselves to subtle, often imperceptible, corruption whether those changes are introduced by malice or negligence. By providing digital signatures for these embeddings we can provide the means to ensure that the data have not been tampered with after they’ve been downloaded from our website.
This is a blog post by aaron cope. It was published on June 15, 2026 and tagged golang, embeddings, pgp, c2pa and rustlang.
Shared vector embeddings updates
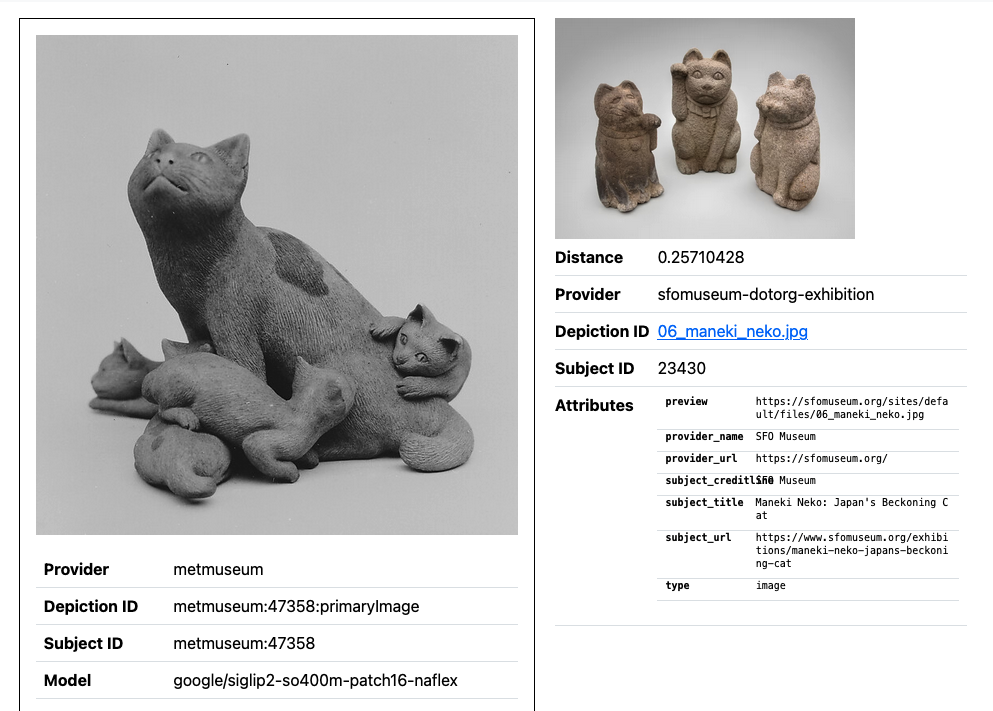
There is a lot of ground to cover in this blog post: The Met publishing their own vector embeddings, SFO Museum publishing 1152-dimension vector embeddings for its images, SFO Museum producing 1152-dimension vector embeddings for NGA and MoMA, and a whole bunch of updates to the tooling used to generate and query vector embeddings targeting local-first and consumer-grade hardware.
This is a blog post by aaron cope. It was published on May 27, 2026 and tagged roboteyes, machine-learning, collection, duckdb, golang, parquet, bleve, embeddings, aws, s3 and s3vectors.
OEmbeddings - What is the least amount of metadata necessary for shared vector embeddings?

This is a blog post describing a proposal for a set of common attributes to include with shared vector embeddings. These common attributes are meant to be the least amount of metadata necessary to provide a simple preview and suitable attribution for the item (an image or text) for which vector embeddings have been produced.
This is a blog post by aaron cope. It was published on April 15, 2026 and tagged roboteyes, machine-learning, collection, oembeddings, embeddings, golang and parquet.
Shared cross-institutional vector embeddings – how we might get there

We are proposing a simple‑is‑best approach to sharing vector embeddings of our collections, a step that moves us closer to realizing the long‑standing ‘holy grail’ of cross‑institutional collections search through vector‑based image similarity.”
This is a blog post by aaron cope. It was published on April 06, 2026 and tagged roboteyes, machine-learning, collection, duckdb, golang, parquet and embeddings.
Updates (and additions) to machine-learning tools running on consumer hardware

These are not “silver bullet” tools. Rather, they endeavour to be part of a set of building blocks for creating an infrastructure that preserves and guarantees the cultural heritage sector some agency in our work.
This is a blog post by aaron cope. It was published on February 10, 2026 and tagged swift, roboteyes, machine-learning, collection, duckdb, golang and embeddings.
Updates to the SFO Museum text and image “embossers” (and a brand new tool for color matching)

In addition to all these changes the go-image-emboss package now includes a new command line tool, called review-colors, to perform image segmentation, color extraction and “snap-to-grid” matching with one or more color palettes for images, displaying all the results in a handy webpage.
This is a blog post by aaron cope. It was published on May 29, 2025 and tagged golang, swift, roboteyes, grpc and color.
Building a custom Placeholder geocoding database

Placeholder is great but there are three things it doesn’t support by default which are pretty important for SFO Museum: The inclusion of airports, historical records and SFO Museum architectural records in the search index. I am happy to say that we are now able to build our own custom Placeholder SQLite databases which address all of these issues.
This is a blog post by aaron cope. It was published on April 28, 2025 and tagged golang, placeholder, geocoding and history.
The SFO Museum Application Programming Interface (API)

Today we are announcing the availability of the SFO Museum Application Programming Interface (API). The API allows developers to access SFO Museum-related data programatically over the internet. The SFO Museum API has actually been around for a while now. It’s what powers the object counts as you add and remove filters on the advanced search page on the Aviation Collection website and is how items are added to and removed from your shoebox from both the Collection and Mills Field websites. The various SFO Museum websites are API consumers just like any other application. We are pleased to be able to (finally) open up access to the API to you and we look forward to seeing what you create with it.
This is a blog post by aaron cope. It was published on January 14, 2025 and tagged golang, python, api, shoebox and picturebook.
Updates to the SFO Museum ActivityPub services

The ability for SFO Museum ActivityPub accounts to both signal and promote one another provides a mechanism where people can subscribe to a single (SFO Museum) account can keep up with everything that all the other (SFO Museum) accounts are talking about. The introduction of a message processing queue, currently just to handle nearby requests, opens up a whole world of possible interactions between people inside (and outside) the terminals and everything SFO Museum has to offer. These small incremental changes and small and incremental in keeping with our goal “to keep things simple and prove that everything can work in a low-cost serverless environment without the need for a lot of babysitting”.
This is a blog post by aaron cope. It was published on November 12, 2024 and tagged activitypub, socialmedia and golang.