Asserting claims: Cryptographically signing the digital artifacts we produce

This is a blog post about museums, and other cultural heritage institutions, cryptographically “signing” the digital artifacts they produce. This is a blog post not just about SFO Museum cryptographically signing the vector embeddings we’ve started publishing but also how we’ve done have, and how we haven’t. There are no scary maths or confusing equations to wrestle with in this post. On the other hand it is still a difficult subject to talk about (cryptographically “signing” digital artifacts) without getting at least a little bit into the weeds. Unfortunately, there isn’t really a “tl;dr” (too long, didn’t read) for this topic.
For the purposes of this post we are talking about signing artifacts using “public-private” cryptography. That’s the name for a mechanism where two inter-related “keys” are generated: One of them is sensitive and private and used to “sign” data; the other is public and meant for distribution and can be used to verify that signature. In between there is a lot of math happening which guarantees the validity of those signatures and works to ensure that they cannot be spoofed. Glossing over many of the details, public-private keys are basically how encrypted connections to websites work. There are some genuine concerns that those guarantees risk being undermined by the advent of quantum computing sooner than anyone would like but for the time being this is what we’ve got.
Why is SFO Museum signing the vector embeddings that we’re producing? To provide an additional guarantee that the data we are publishing is, in fact, the data we published. Vector embeddings are, by their nature, basically impossible to “spot check”. Their size, shape and volume lend themselves to subtle, often imperceptible, corruption whether those changes are introduced by malice or negligence. By providing digital signatures for these embeddings we can provide the means to ensure that the data have not been tampered with after they’ve been downloaded from our website. The mechanism and tools we’ve settled on, at least for exploratory and experimental purposes, are described below. Before I get to that, though, I want to take a detour through something called “C2PA”.

At the end of the last blog post I said: “I really want to believe in the Content Authenticity Initiative (C2PA) project”. C2PA stands for the Coalition for Content Provenance and Authenticity. C2PA is an industry-led initiative to produce the technical standards for publishers to assert cryptographically verifiable claims about subject matter and provenance in digital media files. C2PA doesn’t prevent AI-generated images of things which may or may not exist. It does provide a way for an otherwise trusted source to assert, cryptographically, that a media file was produced by them. The absence of those claims, then, comes to represent the uncertain world of AI-generated slop we are navigating today. The presence of those claims provide, if not absolute certainty then at least, more certainty that both the subject and the provenance of that media are legitimate. Since writing that I have found myself thinking that until C2PA realizes a kind of “Let’s Encrypt moment” it is unlikely to enjoy any kind of mass adoption.
Wikipedia describes Let’s Encrypt as “a non-profit certificate authority run by the Internet Security Research Group (ISRG) that provides X.509 certificates for Transport Layer Security (TLS) encryption without charging fees.” So, basically, public-private key pairs to allow encrypted connections between a web browser and a website. Previous to Let’s Encrypt TLS certificates were both a chore and a recurring annual expense. Over time, it was understood that for the health and benefit of the internet at large the profit-motives that previously dictated (prevented) the wide-spread adoption of TLS needed to be reconsidered. Let’s Encrypt was founded to address both the hassle (better tools) and the cost (free) of creating and maintaining TLS certificates on the grounds that a more secure internet was in everyone’s interest. It’s not that people didn’t understand the benefits of ensuring their websites used encrypted connections. It’s just that until it was both free and easy there were always ample reasons not to bother. As I write this, C2PA is neither free nor easy.
In fairness to the C2PA project, it is still in active development. It has not reached version “1.0” status yet. If the goal is to be able to provide assurances of provenance (and trust) then the consequences of “getting it wrong” are high indeed. This challenge is made harder still by the fact that C2PA traffics in media files (typically but not exclusively images) and parsing media files has long been a place of elaborate, and dangerous, security exploits. For all of these reasons it’s not unreasonable to think that the principals working on C2PA see the current set of technical (and financial) hurdles as a deliberate gating mechanism to keep people away until the dust settles.

C2PA simply isn’t ready for mass adoption yet. Or, perhaps, C2PA is actually designed to only be used by a select group of “authoritative” organizations. Either way C2PA feels like something that museums and other cultural heritage organizations should want to be a part of. I have been watching C2PA for a while but always holding off investing too much time since it always seemed “too soon” for our purposes. The other week, I finally went down the rabbit hole. The result of that journey is that we are still not using C2PA in any kind of production-related capacity. If previously the issue was that things were “too soon” the issue now is that they are still “too hard”.
The C2PA project has been working, in public, to produce functional (and openly licensed) implementations of the specifications they are proposing. One of these implementations is a command line tool called c2patool which does everything you need to add, update and verify claims (assertions) in a media file. c2patool is written in the Rust programming language and all of its heavy-lifting is implemented in a separate library which can be imported into external code, like ours.
We have been able to produce tools in Go which allow us to assign new and updated claims to an image from the command line and to images stored in S3 using an AWS Lambda function. These tools use the underlying Rust implementation bundled as a static library. We have been able to validate those claims using the default test certificates provided in the c2pa-rs package as well as self-signed certificates that I generated myself. That code is not a general-purpose library (and may still have bugs) but has been published as a reference implementation in the spirit of generousity here:
So far, so good. Unfortunately, everything starts to get complicated from here on. C2PA claims may be well-formed, valid and trusted. A trusted assertion is valid and a valid assertion is well-formed. A valid assertion, however, is not automatically trusted. Validation and trust are both a function of the cryptographic (public-private) certificates used to sign the claims. This is similar - but not the same - to the cryptographic certificates used to establish encrypted connections between your browser and a website. More specifically: The certificates you might use for a web server cannot be used to sign C2PA assertions.

Instead you need a certificate whose “Extended Key Usage” (EKU) properties are configured for code-signing or sending email (and not for web connections). These kinds of certificates are not offered by the Let’s Encrypt project or by cloud services like Amazon Certificate Manager. These “special” certificates instead need to be purchased from, and be signed by, one of the vendors on the short list of commercial services recognized as legitimate certificate “authorities”. And they are not cheap; the least expensive option I’ve seen so far is 500$/year.
There might be trusted vendors offering less expensive C2PA-compatible certificates but that doesn’t mean they are automatically trusted by the C2PA project (or the tooling they produce). C2PA maintains its own short(er) list of certificate authorities that are trusted (by C2PA) to sign assertions. If that weren’t enough the safety and security criteria required by these vendors for using and storing “code-signing” certificates are non-trivial at best. There is nothing wrong with these requirements. Code-signing certificates are the certificates used to ensure that critical systems, like your computer’s operating system, haven’t been tampered with so it is in everyone’s interest that they demand and enforce rigor. But like I said in the last blog post I am not sure that these requirements, coupled with the financial burden, won’t put C2PA out of the reach (or bother) of most museums.
One of the reasons for this long-ish detour through the mechanics of C2PA certificates is that, until I learned all of these details the hard way, I was really hoping that SFO Museum could use certificates produced by the Amazon Certificate Manager (ACM) service to both sign C2PA claims added to the images we publish on the collection website and to digitally sign the vector embeddings we have been producing for those images. We cannot, for all the reasons I’ve just outlined.

We are, however, using those certificates to digitally sign the vector embeddings. Technically, you are not supposed to use a web-facing certificate (like the one we created for signatures.sfomuseum.org using ACM) but you can. Depending on how a tool validating signatures interprets the certificates (used to produce the signatures) it may choose to throw an error. This is how the C2PA tooling works but is not the default behaviour for many other tools, so we have opted to take this route if only for the purposes of “kicking the tires” and testing the idea of signing vector embeddings.
Setting aside all the reasons we’re not using C2PA in the first place, you might be wondering why we don’t use C2PA to add signed claims to the Parquet files containing the embeddings themselves. The reason is because C2PA is targeted at media files and does not support derivative or data-based materials like a Parquet file full of vector embeddings. It is unclear whether C2PA will ever support these types of files. In the absence of that support our hope is (was) to be able to use the same signing certificates for both media assets (images) and data products (vector embeddings). For the time being, the financial and administrative hurdles imposed by C2PA make that goal a challenge.
It bears repeating that we are signing these vector embeddings in order to provide an additional guarantee that the data we are publishing is, in fact, the data we published.
Vector embeddings are, by their nature, basically impossible to “spot check”. Their size, shape and volume lend themselves to subtle, often imperceptible, corruption whether those changes are introduced by malice or negligence. Historically we have relied on institutions publishing data on their own websites (which are verified and validated using the same cryptographic certificates we’ve been talking about throughout this blog post) as a guarantee of that data’s fidelity. But what happens after those data are downloaded and live on another computer? The digital signatures are meant to allow you to verify that the files you have on your local computers are still, in fact, the ones that we published on our computers.
Like the vector embeddings, these digital signatures are also published as Parquet files encoding the following data structure:
// Signature encapsulates a digital signature for a `Record` instance.
type Signature struct {
Provider string `json:"provider" parquet:"provider,dict,zstd" bleve:"store"`
// DepictionId is the unique identifier for the depiction for which embeddings have been generated.
DepictionId string `json:"depiction_id" parquet:"depiction_id,dict,zstd" bleve:"store"`
// Model is the label for the model used to generate embeddings for DepictionId.
Model string `json:"model" parquet:"model,dict,zstd" bleve:"store"`
// Return the hex-encoded SHA256 hash of the record that was signed.
RecordHash string `json:"record_hash" parquet:"record_hash,dict,zstd" bleve:"store"`
// Return the detached signature associated with the signed record as an ASCII armor-encoded string
RecordSignature string `json:"record_signature" parquet:"record_signature,dict,zstd" bleve:"store"`
}
For example:
$> duckdb
DuckDB v1.5.3 (Variegata)
Enter ".help" for usage hints.
memory D .mode box
memory D DESCRIBE(SELECT * FROM read_parquet('https://static.sfomuseum.org/embeddings/sfomuseum-collection-1152-siglip2-patch14-20260519-signatures.parquet'));
┌──────────────────┬─────────────┬──────┬──────┬─────────┬───────┐
│ column_name │ column_type │ null │ key │ default │ extra │
├──────────────────┼─────────────┼──────┼──────┼─────────┼───────┤
│ provider │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ depiction_id │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ model │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ record_hash │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ record_signature │ VARCHAR │ YES │ NULL │ NULL │ NULL │
└──────────────────┴─────────────┴──────┴──────┴─────────┴───────┘
Or more concretely, still:
memory D .mode line
memory D SELECT * FROM read_parquet('https://static.sfomuseum.org/embeddings/sfomuseum-collection-1152-siglip2-patch14-20260519-signatures.parquet') LIMIT 1;
provider = sfomuseum-data-media-collection
depiction_id = 1527843173
model = google/siglip2-so400m-patch14-384
record_hash = 329b40db366963d38d70a762ef5703e2937aa96552756fbd4d80c222c5ec3c8e
record_signature = -----BEGIN SIGNATURE-----
MEQCIGeH2Oriy1fMaftEr5JdmQlr2cMsv6SffN3vsVw38Mf9AiA97LRbbGMJD6qZ
G28ht+nL6muojCWoZNN0a1JLbTIN7w==
-----END SIGNATURE-----
The provider, depiction_id and model properties are the same as those found in a Parquet-encoded vector embeddings file.
The record_hash property is the SHA-256 hash of the JSON-encoding of the Record data structure which is derived from any given row in a Parquet-encoded vector embeddings file. In effect this is the unique key for individual embeddings since it is technically possible to generate two (or more) separate vector embeddings for the same (provider, depiction, model) triple since models cannot be guaranteed to return the same embeddings for the same image.
The record_signature property is the PEM-encoded digital signature associated with the record hash.
We have added two new tools to the sfomuseum/go-embeddingsdb package: parquet-sign, which will generate a new Parquet file containing digital signatures for one or more Parquet files containing vector embeddings and parquet-verify, which will use a “signatures” file to validate a Parquet file containing vector embeddings. For example:
$> ./bin/parquet-sign \
-embed-public-key \
-signer-uri 'acm://?region=us-east-1&credentials=session&arn={ARN}' \
-target-bucket-uri file:///usr/local/data/embeddings \
/usr/local/data/embeddings/sfomuseum-collection-512-mobileclip-20260608.parquet
This will produce two files:
sfomuseum-collection-512-mobileclip-20260608-signatures.parquet- The Parquet file containing digital signaturessfomuseum-collection-512-mobileclip-20260608-signatures.pub- The public half of the certificate used to create those signatures
To then verify the data (in sfomuseum-collection-512-mobileclip-20260608.parquet) using those signatures:
$> ./bin/parquet-verify \
-signatures /usr/local/data/embeddings/sfomuseum-collection-512-mobileclip-20260608-signatures.parquet \
-verifier-uri 'x509://?certificate-uri=file:///usr/local/data/embeddings/sfomuseum-collection-512-mobileclip-20260608-signatures.pub' \
/usr/local/data/embeddings/sfomuseum-collection-512-mobileclip-20260608.parquet
As of this writing there are two (technically three) “signer” and two “verifier” implementations: One for x.509 certificates and one for OpenPGP digital signatures. The third signer, as seen in the example above, is for the Amazon Certificate Manager (ACM) service. Under the hood the ACM signer is just an “x.509” signer hiding all the grunt-work of retrieving (x.509) certificates from the ACM service.
Both implementations (x.509 and OpenPGP) are equally valid. The choice to use one over another should only be governed by the mechanics of existing infrastructure and/or the steps necessary to secure and access the private key used to generate those signatures. For example, OpenPGP (or GnuPG… yes, it’s confusing) can feel like it has a less-than-user-friendly learning curve but is also free and openly licensed, doesn’t require the involvement of any third parties and can run locally on your desktop. There isn’t a “right” or “wrong” answer; only trade-offs which will reflect your circumstances. SFO Museum has generated and published digital signatures files, along with the public keys used to verify them, for SFO Museum-specific embeddings, here:
We have also archived the public keys in the Internet Archive’s Wayback Machine. We have not yet generated digital signatures for the vector embeddings we’ve produced for other sources, like MoMA, NGA or the Smithsonian. Maybe we should? Maybe we will if only to highlight why it feels important for institutions to assert, as best they can using the cryptographic means at hand, that the things bearing our names really were produced by us.

google/siglip2-so400m-patch16- naflex model. (See larger version.)
Careful readers will note that we also just announced the publication of vector embeddings for images published by four different Smithsonian units: the National Air and Space Museum, the National Museum of American History, the Smithsonian American Art Museum and the National Museum of Asian Art. These embeddings were produced using data from the Smithsonian’s OpenAccess data initiative. Enjoy!
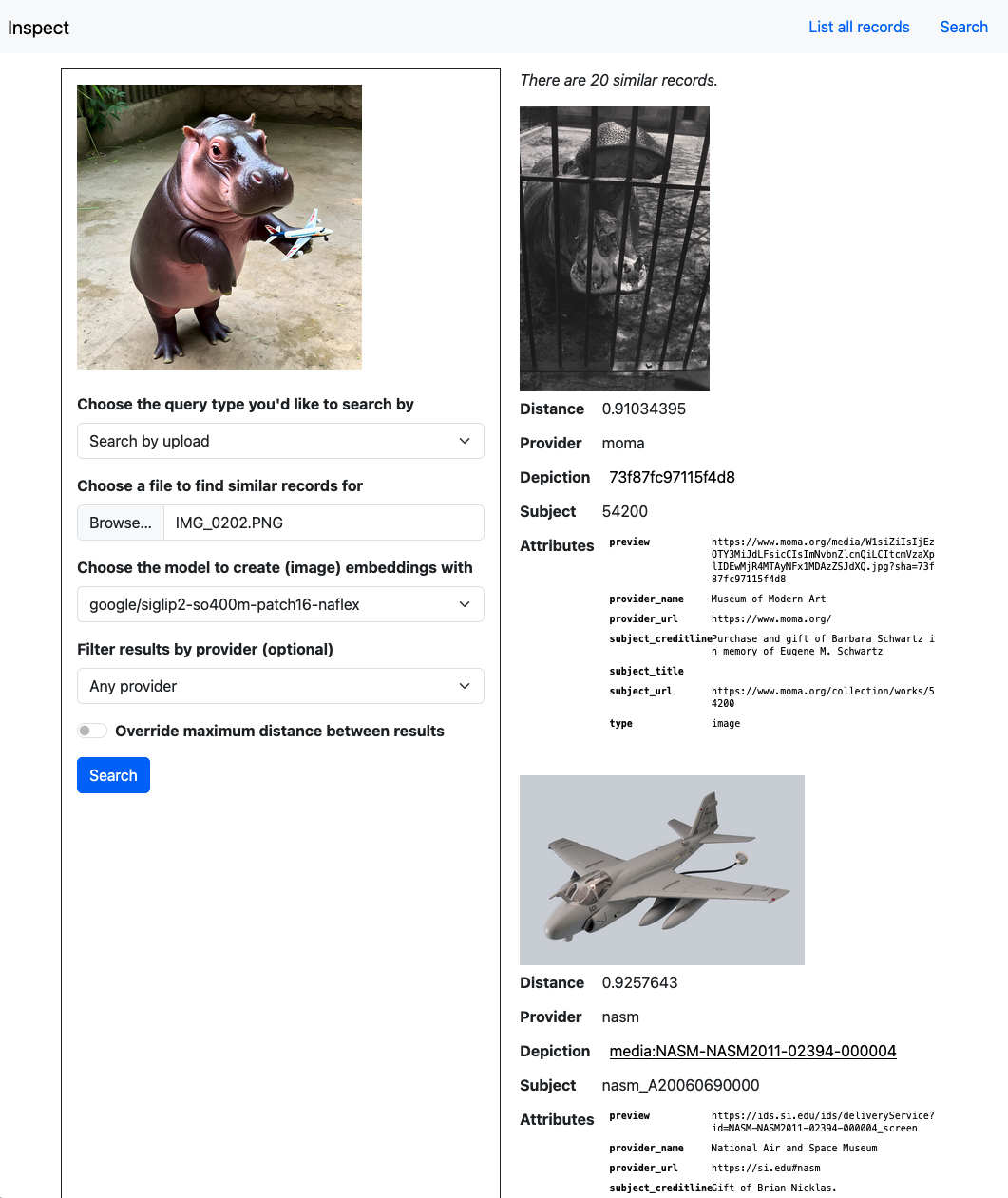
pygmy hippopotamus holding an airplane, according to the
google/siglip2-so400m-patch16-naflex model. (See larger version.)