Shared vector embeddings updates
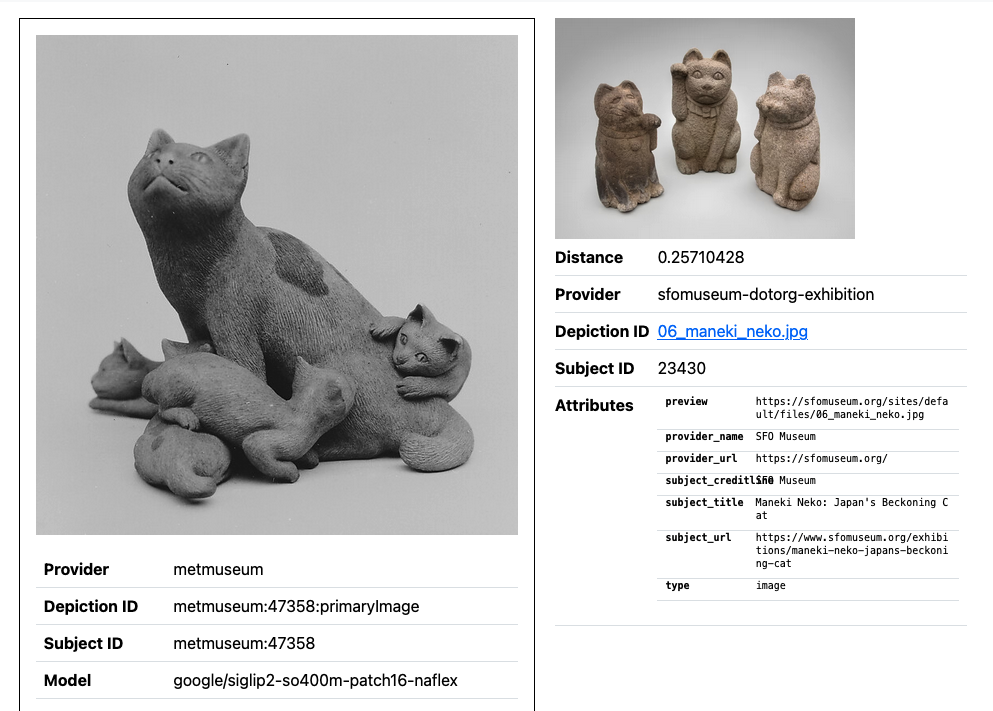
google/siglip2-so400m-patch16- naflex model. (See larger version.)
There is a lot of ground to cover in this blog post: The Met publishing their own vector embeddings, SFO Museum publishing 1152-dimension vector embeddings for its images, SFO Museum producing 1152-dimension vector embeddings for NGA and MoMA, and a whole bunch of updates to the tooling used to generate and query vector embeddings targeting local-first and consumer-grade hardware. Much of this post is technical in nature so I’ve tried to put the less-technical stuff at the top and included a “table of contents” so you can get a feel for the different subjects discussed.
- The Met has published vector embeddings for their collection images
- SFO Museum has published 1152-dimension embeddings for our images
- SFO Museum has produced (and published) 512 and 1152-dimension embeddings for images in the NGA and MoMA collections
- The
go-embeddingsdbpackage now has database implementations for the Bleve database and the AWS S3Vectors service - There are new tools for generating 1152-dimension (SigLIP2) vector embeddings in container environments (specifically Docker and Apple’s
containerframework) - Ongoing and future work
The Met has published vector embeddings for their collection images
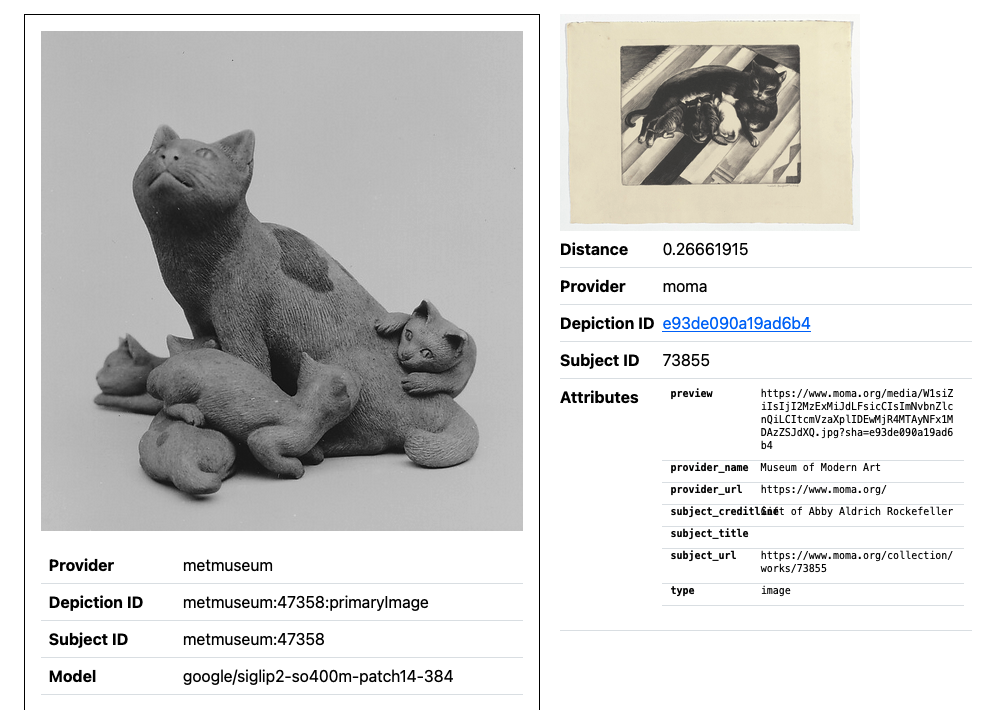
google/siglip2-so400m-patch14-384 model. (See larger version.)
The Metropolitan Museum of Art has published multiple sets of vector embeddings for over 500,000 object images in their collection. These include embeddings produced using a number of different models: Apple’s MobileClip models, OpenCLIP, DINOv2 and Google’s SigLIP2.
In addition to publishing vector embeddings, the Met has also published these data as Parquet files following the formatting rules described in the Shared cross-institutional vector embeddings – how we might get there and OEmbeddings - What is the least amount of metadata necessary for shared vector embeddings? blog posts. This means they can be easily incorporated with many of the tools SFO Museum has produced for working with vector embeddings. Those tools are discussed further below.
Vector embeddings can be downloaded from the Met’s HuggingFace account here:
If you’re not familiar with HuggingFace click the “hamburger menu” on the right-hand side, then click the “Clone repository” link and follow the instructions to download the vector embeddings. For example:
SFO Museum has published 1152-dimension embeddings for our images
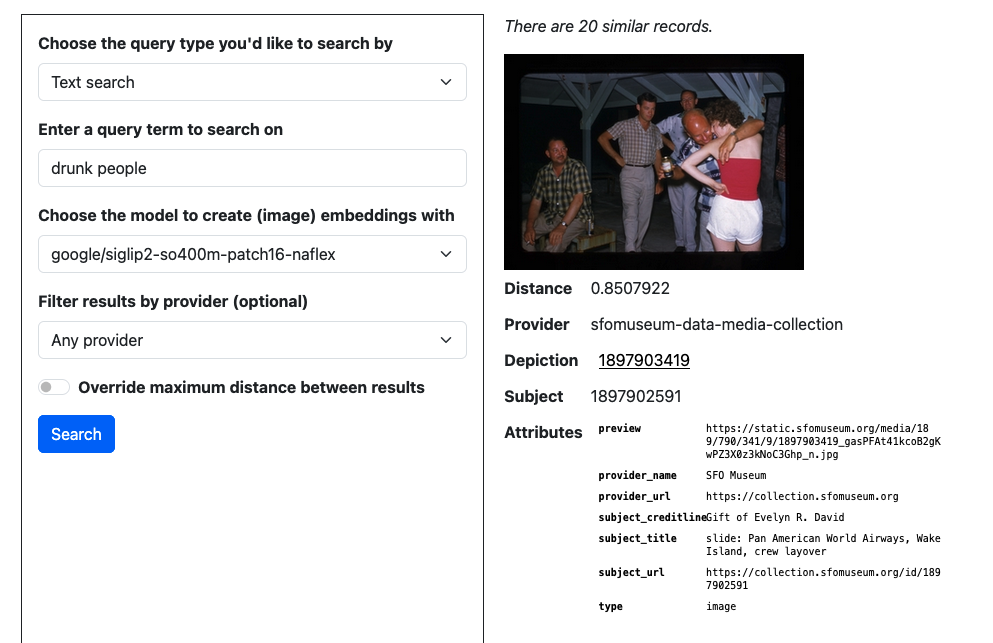
drunk people, according to the
google/siglip2-so400m-patch16-naflex model. (See larger version.)
In addition to the existing 512-dimension MobileCLIP vector embeddings, SFO Museum has also produced two new sets of 1152-dimension vector embeddings, using Google’s SigLIP2 models, for all our imagery (collection objects, Instagram posts, exhibition and installation photos). We have produced embeddings using the -patch14 and -naflex models if only to try and understand their different benefits and trade-offs. For example, the former appears to be better targeted at text-based embeddings and is much slower than the latter at producing embeddings for images. Anecdotally, the latter is also better at “similarity”-based queries. These are available to download as Parquet files from:
SFO Museum has produced (and published) 512 and 1152-dimension embeddings for images in the NGA and MoMA collections
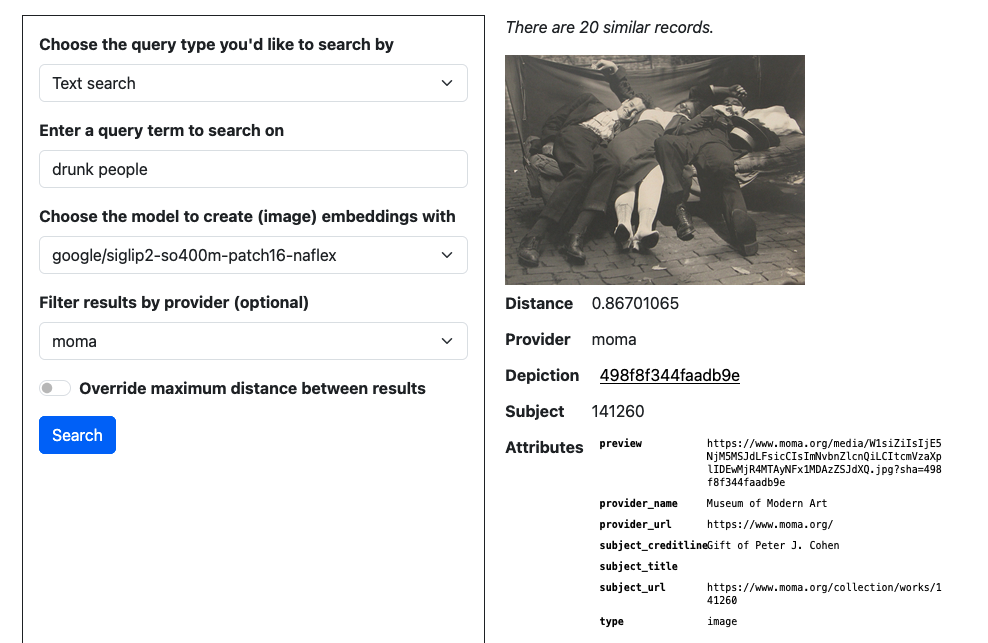
drunk people, according to the
google/siglip2-so400m-patch16-naflex model. (See larger version.)
Both the National Gallery of Art (NGA) and the Museum of Modern Art (MoMA) have published their collections metadata as “open data” releases. We have used those data to generate vector embeddings of the object images described therein. We have generated three sets of 512-dimension embeddings (using Apple’s MobileCLIP s0, s1 and s2 models) and two sets of 1152-dimension embeddings (using Google’s SigLIP2 patch14 and naflex models). Ideally, both of these institutions would, like the Met, produce and publish their own vector embeddings but until then we are happy to share the results of our work. These embeddings are available to download as Parquet files from:
The go-embeddingsdb package now has database implementations for the Bleve database and the AWS S3Vectors service
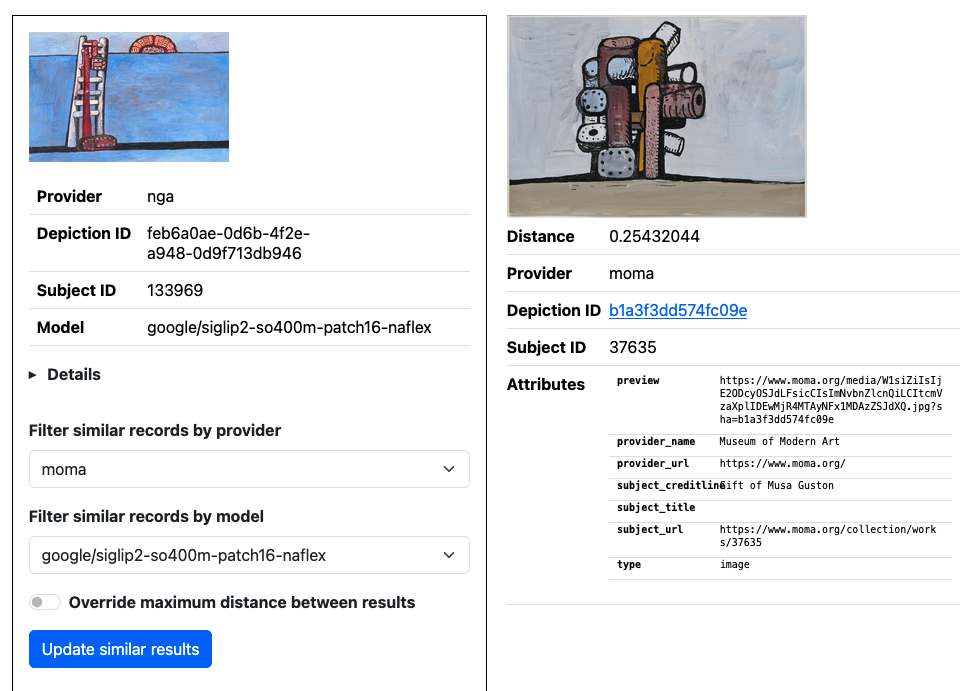
google/siglip2-so400m-patch16-naflex model. (See larger version.)
The sfomuseum/go-embeddingsdb package recently added support for two new database sources: The Bleve document store and the Amazon Web Services (AWS) S3Vectors service. That brings the total number of default database implementations to four:
- DuckDB - Manage vector embeddings using the DuckDB database and the VSS extension. This is the default implementation.
- SQLite - Manage vector embeddings using the SQLite database and the sqlite-vec extension.
- Bleve - Manage vector embeddings using the Bleve database and the faiss library.
- S3Vectors - Manage vector embeddings using the Amazon Web Services S3Vectors service.
The DuckDB implementation is generally faster than SQLite but requires that all your data be stored in memory. That data is periodically exported to disk so that it may be re-imported, at a later date, without indexing all the data from scratch but that import still takes a noticeable amount of time at startup time.
The SQLite implementation has slower query times but stores (and reads) all its data from disk so it is fast to start.
The Bleve implementation has speedy query times, has a fast startup time, doesn’t require loading all the data into memory and doesn’t use an unmanageable amount of disk space. It would be an ideal database layer were it not for the fact that it remains a non-trivial chore to set up because of its dependency on libfaiss. If you can get it to work a Bleve-backed database is pretty great but know that the build process may be a challenge.
The S3Vectors implementation is fast and demonstrates good query times. It is, however, dependent on a commercial service where everything (from storage to queries) is metered. Depending on how your database access is configured, this could lead to very large bills at the end of the month. If you have already made your peace with AWS then it can be a quick and easy way to get started with vector embeddings. The S3Vectors service is also available to web applications running as AWS Lambda Functions (and Function URLs) without the need for any additional AWS services (like a VPC) to broker that access. For example, we are running an internal version of the embeddingsdb-server, for testing purposes, as a Lambda function URL.
SFO Museum has successfully compiled an instance of the embeddingsdb-server, targeting MacOS, which bundles statically linked dependencies to support both locally-available DuckDB extensions (VSS) and Bleve (libfaiss) in a way that the application can be signed, notarized and installed on another machine. We have demonstrated that it is possible but it is still a bit of a pain. In the future we might consider making that signed and notarized binary available for general download but, in the meantime, if you have questions about the process feel free to drop us a line.
SFO Museum has also indexed over 1.5 million vector embeddings – all the (SigLIP2) embeddings published by the Met paired with the embeddings produced by SFO Museum for its own collection as well as the NGA and MoMA – in an AWS S3Vectors bucket. As mentioned, we have proven that it can be queried from the embeddingsdb-server tool running as an AWS Lambda Function URL. We are still evaluating over all costs which is one reason we are not making the URL for that tool public yet. As usual with S3 there is an up-front cost uploading data into a bucket but after that the monthly storage costs seem minimal (or at least manageable). Costs for querying those data are still under review. One attractive feature of the S3Vectors service is that it can be easily incorporated with the AWS hosted OpenSearch database allowing you to store, but still query, vector embeddings outside of the OpenSearch database index (which can reflect a meaningful cost saving).
There are new tools for generating 1152-dimension (SigLIP2) vector embeddings in container environments
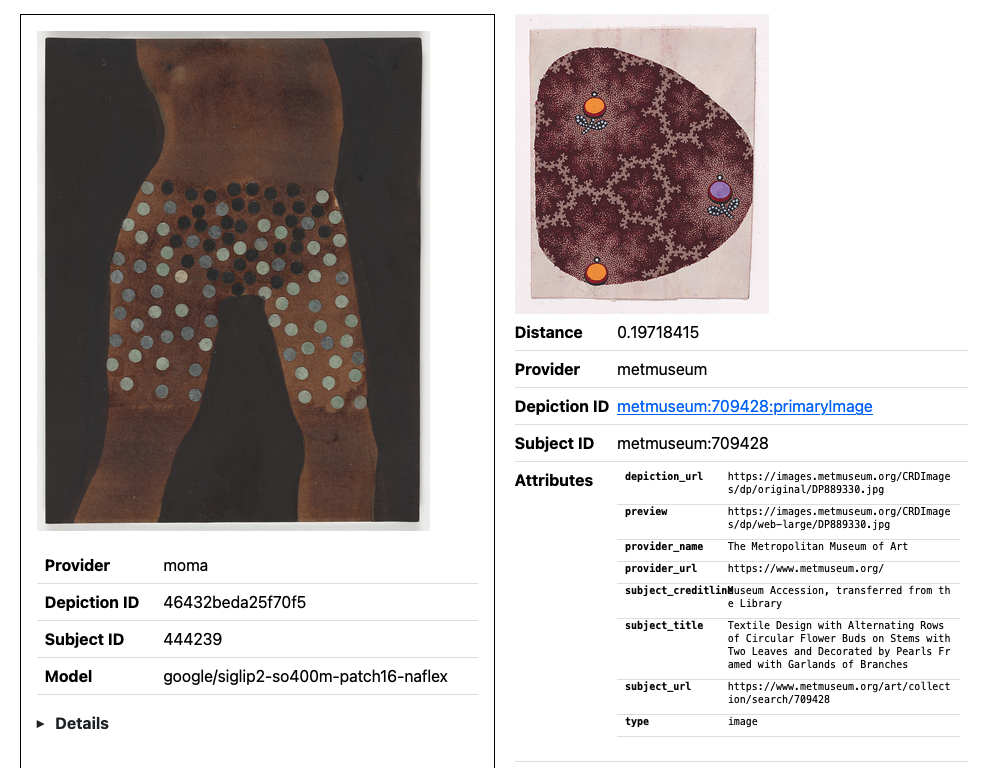
google/siglip2-so400m-patch16-naflex model. (See larger version.)
As previously mentioned the tools in the go-embeddingsdb package do not produce vector embeddings. This process is handled by separate tools. For example the swift-mobileclip package, which can generate 512-dimension embeddings using Apple’s MobileCLIP models. One of the things that we like about the swift-mobileclip tools is that they are entirely self-contained and can be deployed as one-click installations without the need to install additional dependencies.
This remains a relatively novel approach when working with large language models, a fact that reflects the still fast-changing nature of the subject. Typically, working with large language models requires managing specific versions of the Python programming language and installing equally-specific versions of libraries to do all the “heavy-lifting”. Even for people who are comfortable working in computer programming environments this can be a hassle to keep track of. Furthermore the expansiveness of the dependency chain, required by all those libraries, introduces a large amount of third-party code that is usually-probably-okay but in a world where so-called supply-chain attacks against software packages are becoming increasingly common introduces a potentially unacceptable risk.
These concerns are not unique to vector embeddings and it is why “containerized” environments, the best-known of which is Docker, exist. Containers allow you to create self-contained computing environments inside of an external “host”, with no access to that host (your computer). Recently Apple introduced their own container framework called, you guessed it: container.
SFO Museum has published a new set of tools called container-siglip, which are little more than a Dockerfile and some tools to run inside the container it produces. The container itself is a simple Python FastAPI HTTP server to generate vector embeddings (text and image) using one of Google’s SigLIP2 models. The specific model is bundled with the container itself when it is built and the server tool is configured, by default, to only use that local data.
That container can then be run using either Docker or Apple’s container tool. For example, using the latter you might run it this way:
$> container run --rm --memory 6G -p 127.0.0.1:5000:5000/tcp siglip-server-so400m-patch14-384
Loading weights: 100%|██████████|
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:5000 (Press CTRL+C to quit)
INFO: 192.168.64.1:63416 - "POST /embeddings HTTP/1.1" 200 OK
The -p 127.0.0.1:5000:5000/tcp flag instructs the container application to create a bridge between port 5000 on the container and port 5000 on your local computer allowing you to request vector embeddings from the “simple Python FastAPI HTTP server” running on the container. For example:
echo "hello world" | \
./bin/embeddings \
-client-uri 'siglip-client://?server-uri=http://localhost:5000' \
text \
-
...vector embeddings returned here
Running the siglip_server tool through the Apple container framework incurs a noticeable performance cost, compared to running the same code locally on the host machine. This is considered to be an acceptable, or at least known, trade-off. The performance cost should be weighed relative to the security considerations of running code in a container environment and/or the hassle of installing dependencies locally. This will vary from one situation to another.
There are two reasons we like the Apple container framework. As we’ve said before we continue to think there is value in understanding how and where machine-learning tools can be deployed by museums using consumer-grade hardware. There is nothing uniquely special about a Mac Mini. There are other “mini” computer with equal or better computing resources but Apple computers are familiar, easy-to-use and generally fit the budgets of most museums. Having a simple-to-install and relatively easy-to-use container framework produced by Apple itself means it can be deployed with a measure of confidence and understanding that other tools may not enjoy. Additionally, it is possible to save a container to a disk image on one machine and then copy it for use on another machine.
It is not possible to run (Apple) containers as “headless” services yet. That’s because when the container application starts it needs to be able to write to ~/Library/Application Support/com.apple.container/ folder, which won’t exist if you are trying to run things with a “system”-level user (that doesn’t have a traditional GUI login). There is an open ticket related to these issues but, as of this writing, there is no ETA on a resolution.
Ongoing and future work
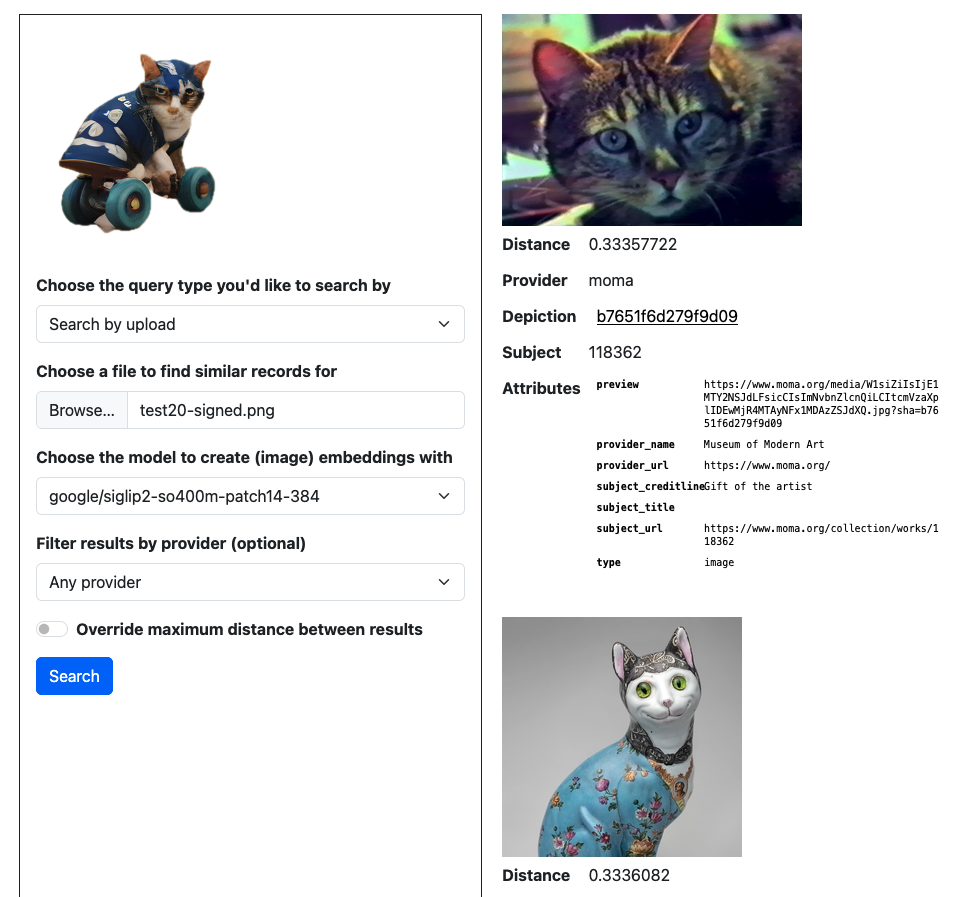
cat playing roller derby, according to the
google/siglip2-so400m-patch14-384 model. (See larger version.)
Naming and metadata conventions
Naming conventions for Parquet-encoded vector embeddings files remain in flux but we are starting to settle on something like this:
{PROVIDER} + "-" {SOURCE} + "-" + {DIMENSIONS} + "-" + {MODEL} + "-" + {YYYYMMDD} + ".parquet"
For example:
nga-opendata-512-mobileclip-20260413.parquet
The use of the - character as a delimiter may be reconsidered but we will live with it for a while and see whether there are any “kinks” which need to be addressed. There is no formal requirement for anyone else to use this naming convention. It just seems like a useful pattern to follow to more easily understand the “shape” of the data in any given Parquet file and if someone else dreams up a better set of naming conventions we’ll use those instead.
We have also updated all the tools in the sfomuseum/go-embeddingsdb package which write Parquet to track and record statistics about the data being written. These stats are then stored in that Parquet file’s KeyValueMetadata block. We’ve also included a parquet-append-stats tool which will crawl an existing Parquet, derive relevant statistics and publish them to a new Parquet file. For example:
$> ./bin/parquet-append-stats \
-output with-stats.parquet \
/usr/local/data/embeddings/nga/nga-opendata-512-mobileclip-20260413.parquet
And then:
$> ./bin/parquet-metadata -key-value ./with-stats.parquet | jq
{
"embeddingsdb:model:apple/mobileclip_s0:dimensions": "512",
"embeddingsdb:model:apple/mobileclip_s0:providers": "nga",
"embeddingsdb:model:apple/mobileclip_s1:dimensions": "512",
"embeddingsdb:model:apple/mobileclip_s1:providers": "nga",
"embeddingsdb:model:apple/mobileclip_s2:dimensions": "512",
"embeddingsdb:model:apple/mobileclip_s2:providers": "nga",
"embeddingsdb:models": "apple/mobileclip_s2;apple/mobileclip_s1;apple/mobileclip_s0",
"embeddingsdb:provider:nga:models": "apple/mobileclip_s2;apple/mobileclip_s1;apple/mobileclip_s0",
"embeddingsdb:providers": "nga"
}
As with the naming conventions there is no formal (or formalized) structure to these metadata yet. If people have strong feelings or opinions about what should be included we welcome your input.
Better caching for The SFO Museum tools for harvesting vector embeddings
The tools for “harvesting” vector embeddings in the sfomuseum/go-embeddings-harvest package have been updated to keep a local cache of the images they use to produce embeddings. This caching layer has been released as a standalone package called sfomuseum/go-blobcache and allows for data to be cached on the local filesystem or using a number of third-party storage services and Amazon S3, Google Cloud or Microsoft Azure.
Support for multiple dimensions in the embeddingsdb-server tool
There is a proof of concept implementation of the embeddingsdb-server which supports multiple vector embeddings dimensions. Under the hood there are still multiple database “instances” but the code handles all the leg-work of figuring out which database to talk to based on the action being performed. There are a number of user-interface details which need to be accounted for but, hopefully, that work will be completed soon.
C2PA
I really want to believe in the Content Authenticity Initiative project. It is seeing a lot of active development inside of news organizations and is being considered by the Library of Congress. It is also not yet suitable for use with vector embeddings. Arbitrary JSON data structures (like vector embedding records) are not supported by C2PA which is primarily concerned with media files. C2PA also relies on public/private key cryptography which makes sense but, whose demands and security requirements I fear will be beyond the time and means of many organizations.
We are working on tools to generate and publish cryptographic signatures using GPG-style public-private keys. This approach shares similar setup, security and maintenance challenges but it offers the ability to validate that any given vector embedding that we produce and published really did come from SFO Museum. We expect that work to be released shortly.