Archiving social media accounts at SFO Museum – Take two
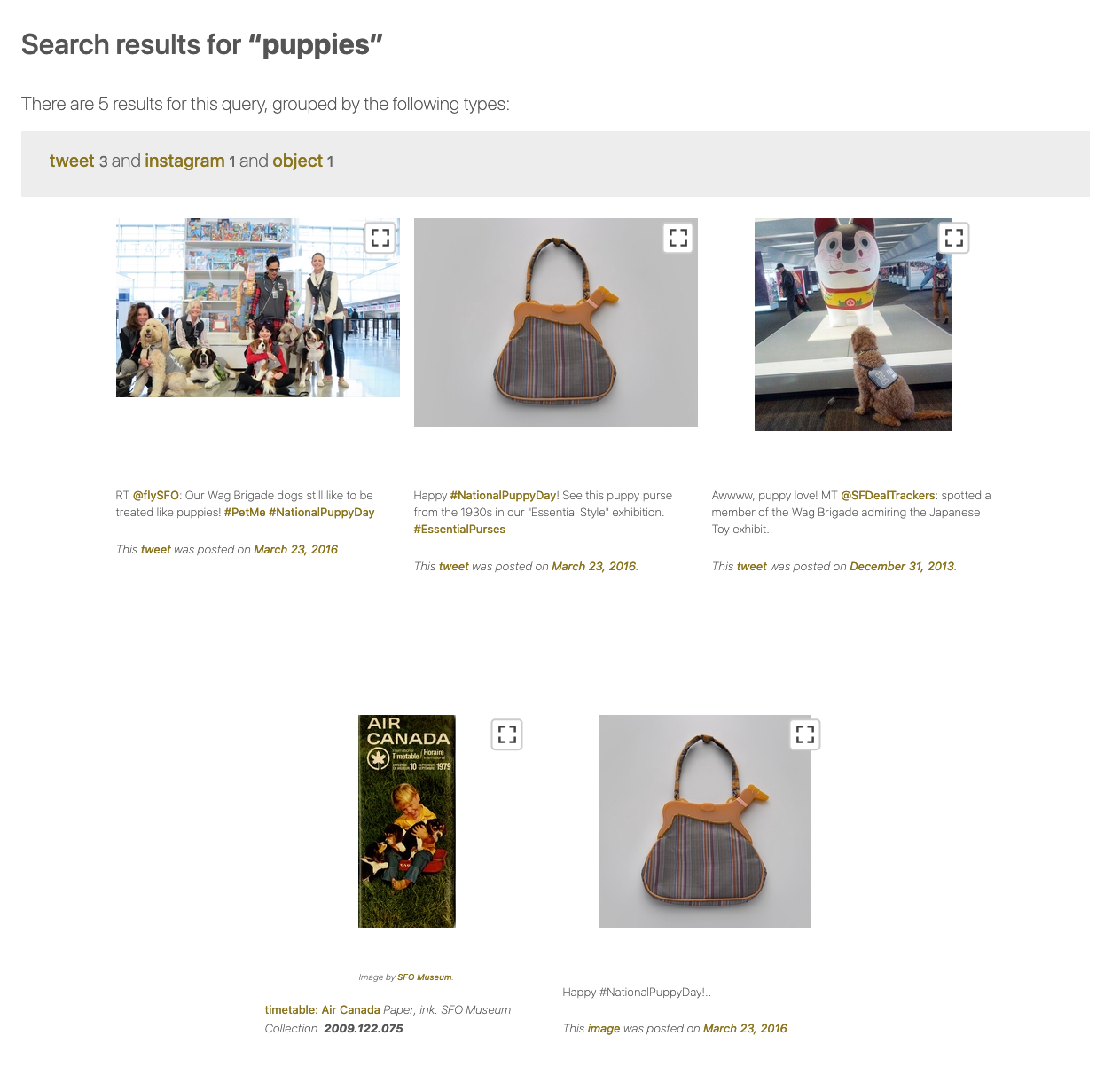
Two weeks ago we updated the @sfomuseum Twitter archives on the Mills Field website. In addition to refreshing the data we also made all the images associated with those Twitter posts “zoomable” and we integrated the Twitter archive with the default search results on the Mills Field website. A week ago we did the same thing with the @sfomuseum Instagram account, adding eight years of Instagram posts to the mix including dedicated pages for each of the hashtags that are associated with a given post. (We haven’t added tag pages for the Twitter archive yet but we will soon.) Now that these archives are part of the Mills Field website we can start to more tightly link them, beyond just tags, with everything else in our collection. We can also geotag these posts which will be especially fun for things like the #behindthescenes pictures.
This is an extension to and a revisiting of the work we started in 2019 when we wrote this about the museum’s social media accounts:
It is important to recognize that Bao’s work is not simply “non-institutional contextualization of digitized collection objects” but an important contribution, one that is central to the museum’s mission. Darren’s comments, though, served to highlight the fact that we haven’t done a great job of “capturing” or “archiving” any of it [on our own website].
The process to import these archives isn’t automated yet but I would like it to be, shortly. It will probably take another two or three iterations to work out the remaining kinks but the goal is for Bao, who manages all our social media accounts, to be able to request an export of the museum’s data from Twitter or Instagram and upon receipt upload that archive to a service we control which will take care of processing images and indexing the posts on the Mills Field website.
In principle we could do this in near real-time using the Twitter API but since there is no equivalent service for Instagram it seems easier to standardize around working with the static archives that each service publishes. It fosters a practice of actively requesting backups of our activity on these services, as opposed to relying on a mysterious automated system running in the background. I also like that it mirrors our own practice of building services and functionality, like the Mills Field website, from the same open data that we publish for other people to use.
The rest of this blog post is pretty technical so if that’s not something that interests you we invite you to spend some time spelunking through almost nine years of Twitter and Instagram posts.

We were able to re-use most of the same code for importing the Twitter archives to import the Instagram archives. Each service has its own unique quirks so there are still two distinct code branches but gradually, as we learn by doing, we are building up layers of common functionality that can be used with both services.
Two of those layers are the go-sfomuseum-instagram and go-sfomuseum-twitter packages. These are first bits of code that we pass the Instagram media.json and Twitter tweet.js metadata files through in order to modify that data or append new properties. In the case of Instagram that means:
- Generating and appending a
media_idproperty derived from a post’s image filename. - Generating a Unix timestamp property from a post’s
taken_atproperty. - Generating and appending a list of
hashtagsandusersproperties derived from a post’s caption. - Generating and appending an
excerptproperty derived from a post’s caption.
These are all properties missing from the metadata that Instagram publishes. They are all things that SFO Museum needs to import Instagram posts but they seem broadly useful, in a number of scenarios, so we’ve made them available in code that isn’t SFO Museum-specific. In the case of Twitter the modifications include:
- Generating a Unix timestamp property from a post’s
created_atproperty. - Determining and appending a
unshortened_urlproperty to eachentities.urlentry for a post.
Overall, the Twitter archive metadata is more robust and comprehensive with things like tags and users mentioned in a post separated in to their own machine-readable properties. This approach is also applied to URLs and each entry in the entities.url array contains its own url, display_url and expanded_url properties. Many of our Twitter posts contain shortened URLs that we created, at the time, but I feel like it’s important to resolve all those URLs so people can see for themselves where a link will take them. Our Twitter ingest code uses another library we’ve published, called go-url-unshortener, to follow a shortened URL back to its source and then appends that value to the appropriate entities.url property.

These tools are available as libraries written in the Go programming language but we’ve also made the functionality available as standalone command line applications. The approach taken with these tools follows work done elsewhere to process the Smithsonian’s OpenAccess public data set. The size and volume of the OpenAccess data has prompted Smithsonian to publish that data as a series of compressed, line-delimited JSON records in a number of nested folders. In order to make the data a little easier to work with I wrote a tool, called emit, to take care of all the details of crawling the data and simply publish each record to STDOUT where it can be consumed by another process.
Here’s an example of what that looks like processing everything in the National Air and Space Museum collection as JSON, passing the result to the jq tool, searching for things with “space” in the title using the grep tool and finally sorting the results using the sort tool:
$> bin/emit -bucket-uri file:///usr/local/OpenAccess \
-json \
-validate-json \
metadata/objects/NASM/ \
| jq '.[]["title"]' \
| grep -i 'space' \
| sort
"Medal, NASA Space Flight, Sally Ride"
"Medal, STS-7, Smithsonian National Air and Space Museum, Sally Ride"
"Mirror, Primary Backup, Hubble Space Telescope"
"Model, 1:5, Hubble Space Telescope"
"Model, Space Shuttle, Delta-Wing High Cross-Range Orbiter Concept"
"Model, Space Shuttle, Final Orbiter Concept"
"Model, Space Shuttle, North American Rockwell Final Design, 1:15"
"Model, Space Shuttle, Straight-Wing Low Cross-Range Orbiter Concept"
"Model, Wind Tunnel, Convair Space Shuttle, 0.006 scale"
"Orbiter, Space Shuttle, OV-103, Discovery"
"Space Food, Beef and Vegetables, Mercury, Friendship 7"
"Spacecraft, Mariner 10, Flight Spare"
"Spacecraft, New Horizons, Mock-up, model"
"Suit, SpaceShipOne, Mike Melvill"
Both the go-sfomuseum-instagram and go-sfomuseum-twitter packages have their own equivalent “emit” tools which allow a user to take advantage of the code we’ve written without necessarily having to write custom code in Go to process the output. Here’s what the Instagram tool looks like:
$> ./bin/emit \
-append-all \
-expand-caption \
-json \
-format-json \
-media-uri file:///usr/local/instagram/media.json
| jq
{
"caption": {
"body": "In 1994, Gilbert Baker, the original creator of the rainbow flag and a team of volunteers created a mile-long rainbow flag for the 25th Anniversary of the 1969 Stonewall riots. The flag was carried by 5,000 people on First Avenue in New York City. Baker worked tirelessly to ensure the rainbow flag would become a powerful and enduring symbol of pride and inclusion that transcends languages and borders, gender and race, and now, four decades after its creation, generations. Courtesy of Mick Hicks. See \"#ALegacyOfPride: #GilbertBaker and the 40th Anniversary of the #RainbowFlag\" on view pre-security in the International Terminal. http://bit.ly/RainbowFlagSFO",
"excerpt": "In 1994, Gilbert Baker, the original creator of the rainbow flag and a team of volunteers created a mile-long rainbow flag for the 25th Anniversary of the 1969 Stonewall riots.",
"hashtags": [
"GilbertBaker",
"RainbowFlag",
"ALegacyofPride",
"gaypride",
"lgbtpride",
"pride",
"LGBT",
"🏳️🌈",
"👭",
"👬",
"👩❤️👩",
"👩❤️💋👩",
"👨❤️👨",
"👨❤️💋👨"
],
"users": []
},
"taken_at": "2018-09-20T03:40:04+00:00",
"location": "San Francisco International Airport (SFO)",
"path": "photos/201809/0ebfa6dda7247127fb67475768299db2.jpg",
"taken": 1537414804,
"media_id": "0ebfa6dda7247127fb67475768299db2"
}
... and so on
And this is what the Twitter tool looks like:
./bin/emit \
-append-all \
-json \
-format-json \
-tweets-uri file:///usr/local/twitter/data/tweet.js
[
{
"created_at": "Mon Sep 19 19:21:04 +0000 2011",
"display_text_range": ["0", "88"],
"entities": {
"hashtags": [],
"symbols": [],
"urls": [
{
"display_url": "bit.ly/q8nobK",
"expanded_url": "http://bit.ly/q8nobK",
"indices": ["68", "88"],
"url": "http://t.co/aGv43tHf",
"unshortened_url": "https://www.flysfo.com/web/page/sfo_museum/exhibitions/terminal1_exhibitions/B3_archive/robert_apte/01.html"
}
],
"user_mentions": []
},
"favorite_count": "0",
"favorited": false,
"full_text": "Is anyone else hot? How about an Antarctic iceberg to cool you off: http://t.co/aGv43tHf",
"id": "115868023763632128",
"id_str": "115868023763632128",
"lang": "en",
"possibly_sensitive": false,
"retweet_count": "0",
"retweeted": false,
"source": "\u003ca href=\"https://about.twitter.com/products/tweetdeck\" rel=\"nofollow\"\u003eTweetDeck\u003c/a\u003e",
"truncated": false,
"created": 1316460064
}
...and so on
]
There are many other steps in our import process, notably around processing images and making them “zoomable”. Much of that process is SFO Museum-specific but where there are common patterns and approaches that other museums and cultural heritage institutions can use we’ll write about them soon.

This first stage of “prepping” the data for ingest, though, is something we probably all want to do so we are happy to share what we’ve developed so far.