Using the Placeholder Geocoder at SFO Museum

This is a long and technical blog post. The short version is: It is now easy, possible and inexpensive to install and operate a “coarse” geocoding service, with global coverage, support for multiple languages and stable permanent identifiers using openly licensed data, both locally and in ☁️ the cloud ☁️. We’ve made some additional tools to complement this reality and waded through some of the muck of modern software development so you don’t have to.
In August of this year, the nice folks at Geocode Earth published a blog post titled “An (almost) one line coarse geocoder with Docker”. Geocoding is the term of reference to describe the process of converting an address or a place name in to an unambiguous identifier, typically latitude and longitude coordinates.
Stephen Hess’s “Geocoding for Polyglots” is a good introduction to the subject if you’re curious to know more about how geocoding works. Stephen and the Geocode Earth team all worked together at Mapzen on the Pelias search engine. (I also worked at Mapzen.)
The act of geocoding is further distinguished between “street level” geocoding and “coarse” geocoding. According to the Geocode Earth blog post:
A coarse geocoder only supports cities, countries and other administrative areas, so it includes a lot less data than a full geocoder with addresses, streets, points of interest, and so on.
The blog post goes on to say:
The Placeholder service needs data in order to run. In particular, it expects data from the Who’s on First gazetteer. The Who’s on First project is an active, growing open-data project that was started along with Pelias at Mapzen. … The Who’s on First project has a lot of great properties: stable identifiers, very high quality geometries, excellent structures for handling disputed territories, translations in multiple languages including official, preferred, and colloquial variants, and much more.
Which is exciting for us since we are actively using Who’s On First in our own efforts. We are making “place” the joint around which everything in our collection pivots but a lot of the location data in our collection (in all collections!) is still encoded as text and phrases meant for humans. “Words for humans” is a good thing but the opportunity that geocoding affords us is the ability to marry words for humans and machines both (names and labels and stable permanent unamibiguous identifiers).
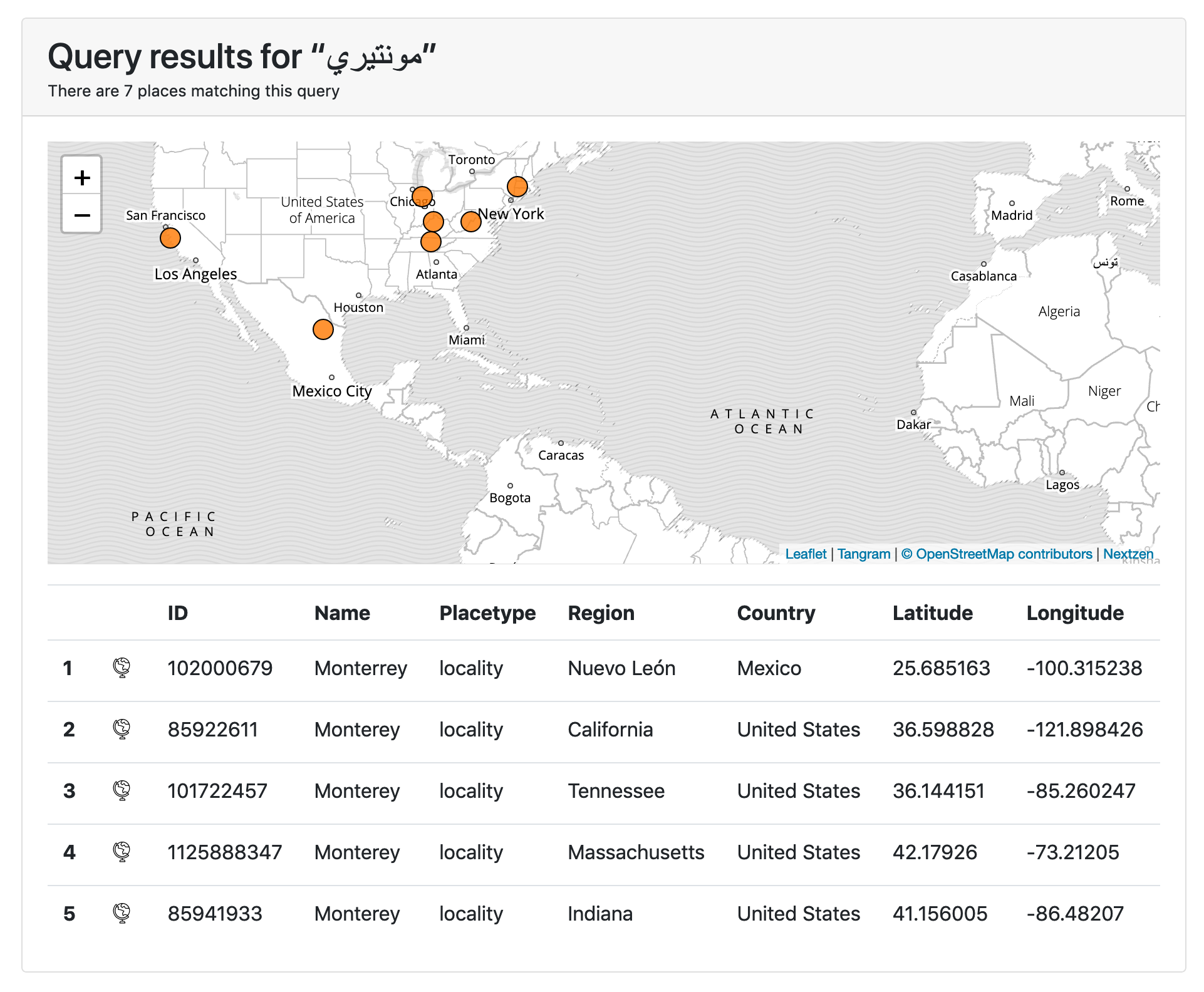
For example there are 70 other places, in six different countries, outside of New York City called “Brooklyn”. The city of Monterey, in California, can also be referred to as “モンテレー” in Japanese or “مونتيري” in Arabic. Creating stable referents for the many ways we refer to the same thing is exactly what the Who’s On First project is for. A geocoding service that “speaks” Who’s On First, that will return a stable permanent identifier with each search result, is pretty great and will help us to improve the location metadata associated with our collection objects.
In addition to being committed to open source software the Geocode Earth team have also made distributions of the data they use to run their services available. This includes data used by the Placeholder geocoder. So, the gist of their blog post is that you can download the data and run it alongside a Docker-ized version of the Placeholder software and just like that you have a coarse geocoder available for all your needs!

Did you notice the way I just said “Docker-ized”?
Docker is both a service and an application for running virtual machines which are referred to as “containers”. A container is basically a freeze-dried virtual computer that contain only that which is absolutely necessary to run a pre-defined set of applications. Tools like Docker take care of “thawing” (and re-freeze-drying) containers and running the software they contain. It’s a pretty clever abstraction and managing the operation of containers, as a service, has been adopted by all the different ☁️ cloud ☁️ providers.
Since you can also run Docker on your local machine it offers the ability to work with all kinds of applications and services that a person might not otherwise want or know how to install, including a tool like the Placeholder geocoder which has a long list of dependencies it needs in order to run.
I mention all of this because after reading the Geocode Earth blog post I thought: We should set up an instance of Placeholder for SFO Museum. Although the Geocode Earth team publish an official Placeholder “container” and the Placeholder application has its own web interface we developed our own versions of each. They are:
This is SFO Museum’s Dockerfile for running the (Pelias) Placeholder service. This creates a container image with the Placeholder software and the SQLite database it uses stored locally (to the container). That means it creates a container image that is very very big. This may not be the container image you want to use. We may not use it, in time.
And:
This is a Go package that provides a simple web application for querying a (Pelias) Placeholder server and uses Bootstrap, Leaflet, Tangram and Nextzen tiles to render pages and maps. All (JavaScript and CSS) assets are bundled locally with the application and it is possible to configure the application to serve and cache local copies of Nextzen tiles.
There is also a separate package for talking directly to the Placeholder service programatically that is used by the go-placeholder-client-www tool:
Go package for talking to a Placeholder endpoint.
Once everything is installed and running it looks like this:

The Brooklyn that most people think of in New York City (not shown) has ID 421205765 to distinguish it from the Brooklyn in Connecticut with ID 404495913, and so on.
Did we mention “support for not-English languages” ? For example if I query for http://localhost:8080?text=مونتيري the results look like this:
Did you notice something about the go-placeholder-client-www tool? It’s a relatively simple web application that depends on three separate JavaScript frameworks, two different services and a whole other cartography component. They are:
- Placeholder – The coarse geocoder we’ve been discussing so far.
- Bootstrap – A framework for developing responsive and mobile websites.
- Leaflet – A framework for web-based mapping applications.
- Tangram – A framework for styling and rendering data in web-based mapping applications.
- Nextzen – A free and open provider of geographic data for web-based mapping applications.
- Tangram map styles – The cartography and styles used by Tangram to render data provided by Nextzen. These are also referred to as “scene files”.
Like Pelias and Who’s On First both Tangram and Nextzen (then known as Tilezen) began life at Mapzen.
For most of the last decade the conventional wisdom has been to load each of these pieces remotely. Usually these pieces are hosted by some sort of third-party content distribution network (or CDN) to help speed things up and the guts of an application are often little more than the glue that binds all these remote bits of functionality together. It’s a fine way of doing things but it’s not the way that I wanted to set up a Placeholder service for the museum.
Instead I wanted:
- To run a local copy of Placeholder.
- For all of the Javascript dependencies (Bootstrap, Leaflet, Tangram) to be bundled with the application and served locally.
- To be able to read and write cached tiles from Nextzen.
- To be able to do all of this both locally, on a remote server and in ☁️ the cloud ☁️.
We did things this way because each of the six dependencies listed above are important pieces of the application we’ve developed. Some are less critical than others in that they could be replaced, relatively easily, with an alternative should the need arise but… you know, we’re busy running a museum.
So, the docker-placeholder Dockerfile accomplishes #1 (and #4) :
$> docker run -it -p 3000:3000 placeholder npm start --prefix /usr/local/pelias/placeholder
> pelias-placeholder@0.0.0-development start /usr/local/pelias/placeholder
> ./cmd/server.sh
2019-11-01T21:53:22.201Z - info: [placeholder] [master] using 2 cpus
2019-11-01T21:53:22.250Z - info: [placeholder] [master] worker forked 24
2019-11-01T21:53:22.251Z - info: [placeholder] [master] worker forked 25
2019-11-01T21:53:22.807Z - info: [placeholder] [worker 24] listening on 0.0.0.0:3000
2019-11-01T21:53:22.808Z - info: [placeholder] [worker 25] listening on 0.0.0.0:3000
The go-placeholder-client-www package does #2 through #4:
$> go run -mod vendor cmd/server/main.go \
-nextzen-apikey {NEXTZEN_APIKEY} \
-proxy-tiles \
-proxy-tiles-dsn 'cache=blob blob=file:///tmp/nextzen'
2019/11/01 14:44:52 Listening on http://localhost:8080
The important part here is that everything is bundled in to a single application, not that there aren’t other equally valid ways of doing the same thing.
Once it’s all up and running when I visit http://localhost:8080/?text=san+diego in my web browser I see this:
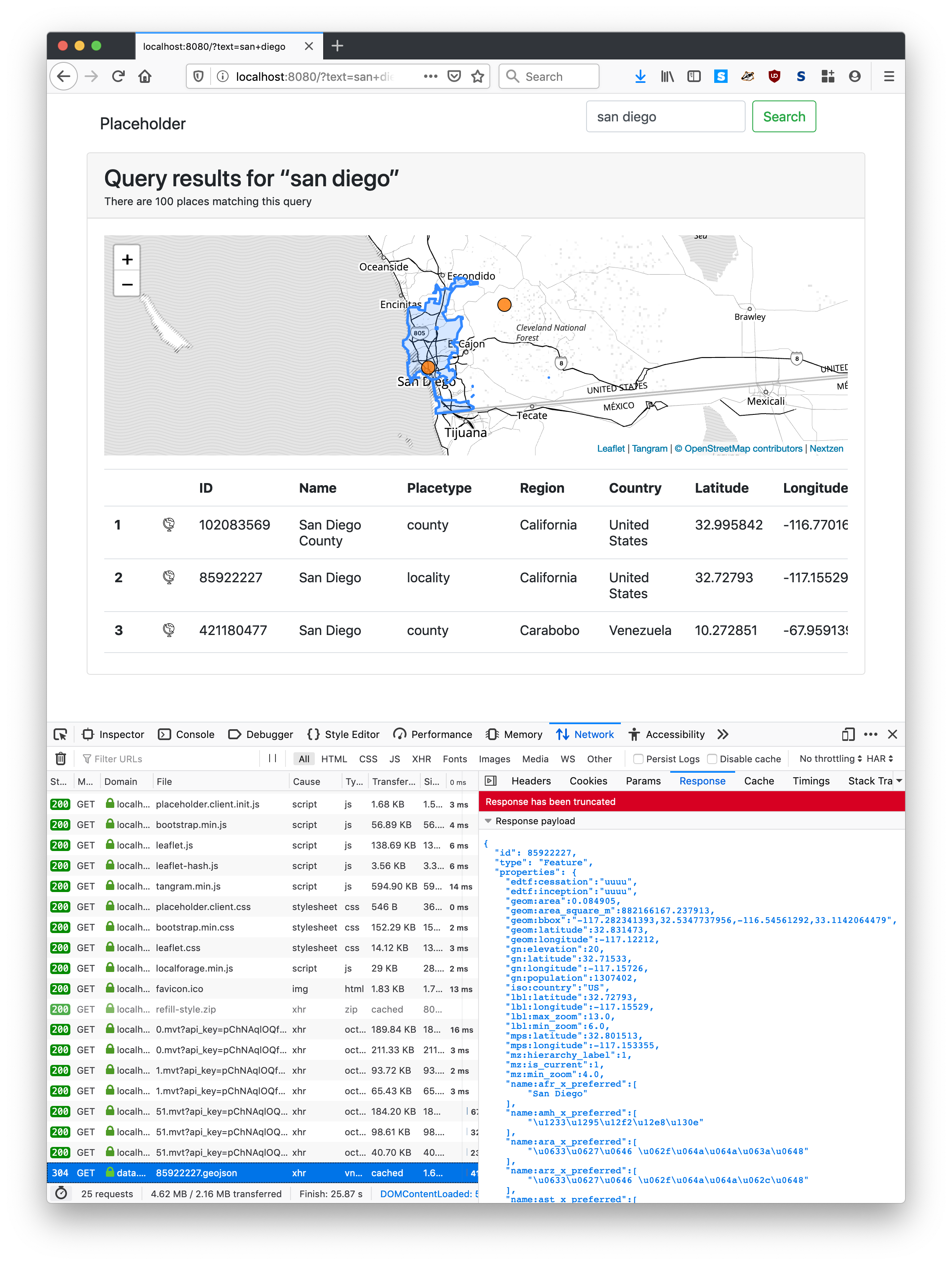
If you look closely at the screenshot you can see that the only thing that is loaded remotely over the network is the Who’s On First gazetteer record for San Diego. It is possible to set up a local copy of WOF data files but we haven’t yet.
In the example above we’ve passed a -proxy-tiles flag which is a signal to the server tool to cache and re-use Nextzen tiles locally. Under the hood the caching mechanism is using the Go Cloud “blob” abstraction for data storage.
> find /tmp/nextzen -name '*.mvt' -print
/tmp/nextzen/7/21/51.mvt
/tmp/nextzen/7/23/51.mvt
/tmp/nextzen/7/22/51.mvt
/tmp/nextzen/1/0/0.mvt
/tmp/nextzen/1/0/1.mvt
/tmp/nextzen/1/1/0.mvt
/tmp/nextzen/1/1/1.mvt
In these examples, we are using the local filesystem but the Go Cloud layer allows us to swap that out for a number of other sources and services with a minimum of fuss. That’s important because we want to able to host the go-placeholder-client-www server using Amazon Web Services (AWS) and cache Nextzen tiles in an S3 bucket.
The good news is: It works and the few remaining “gotchas” are minor to the point of being insignificant or pedantic. The bad news is: The bad news isn’t so bad now that we’ve mostly figured things out and you don’t have to. So, it’s kind of good news with the lesson being that ☁️ the cloud ☁️ is never as easy as anyone says it is.
Some of the issues we’ve encountered along the way might have been easily remedied if we chose to “go all in” with AWS (or any other ☁️ cloud ☁️ provider) so it’s imporant to state up front: We aren’t willing to do that. Additionally I don’t believe an “all in” approach with ☁️ cloud ☁️ services benefits the cultural heritage sector in the long term.
There’s a longer discussion that needs to be had sector-wide about the how and why this is the case but it can largely be summed up as “vendor lock-in” and the inability of an institution to wiggle free of vendor lock-in once it happens. Our goal is to understand the ways we need develop and deploy the technical scaffolding to service our specific efforts without letting the nuances of any given service provider become a finger trap.
As such there’s a lot of effort to recognize and enforce “layers of separation” that incur a non-zero cost in the short-term but that we believe will be worth it over the long-term.
The first “just get it to work” architecture, for running Placeholder and the Placeholder client in AWS, looked like this:
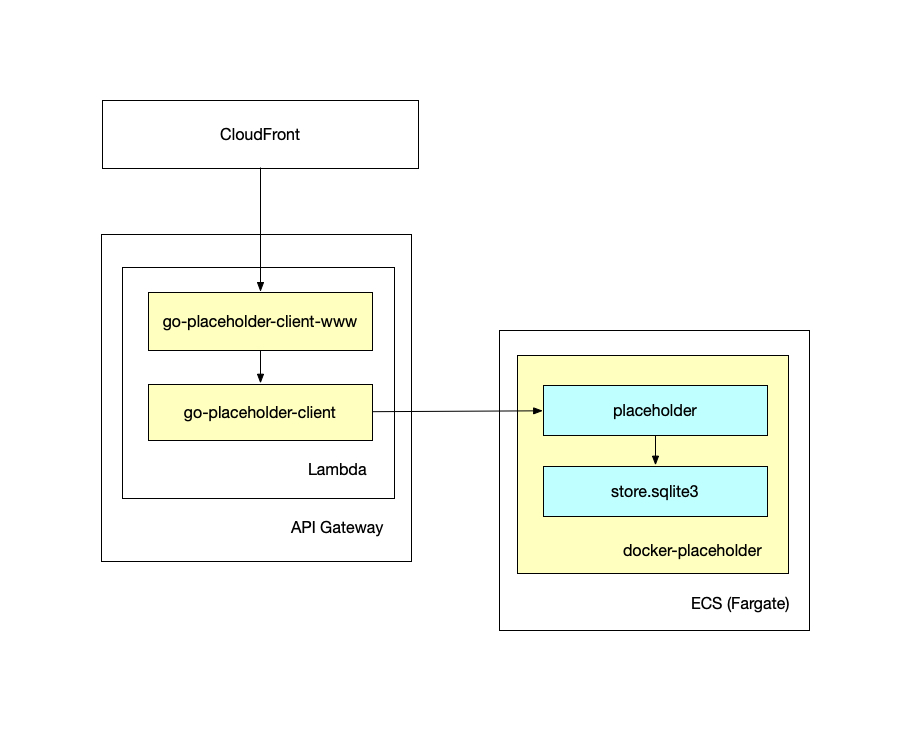
Warning: There is a small hurricane of AWS-related product names that follows. If you don’t know what a particular term means they are all easily findable and well-documented online.
This setup runs the server tool as a Lambda function fronted by an API Gateway that is, in turn, fronted by a CloudFront distribution. The Placeholder service itself is deployed as a long-running server using the Fargate ECS service (to run the docker-placeholder container).
The problem with this setup is that pending patches to the way that Tangram loads scene files, there is no way to tell API Gateway to send those map styles (which are bundled in to the go-placeholder-client-www tool) as binary data instead of as Base64 encoded string. All of which makes Tangram very confused causing it not render any data at all.
The only option here is to load scene files hosted on the Nextzen website. To be clear: Having to fetch the scene files remotely is not the end of the world but since the exercise is to try and set things up so that they are completely self-contained it’s not ideal.
The second, more recent, architecture looks like this and illustrates all the various components in a little more detail (you can see a full-size version here):
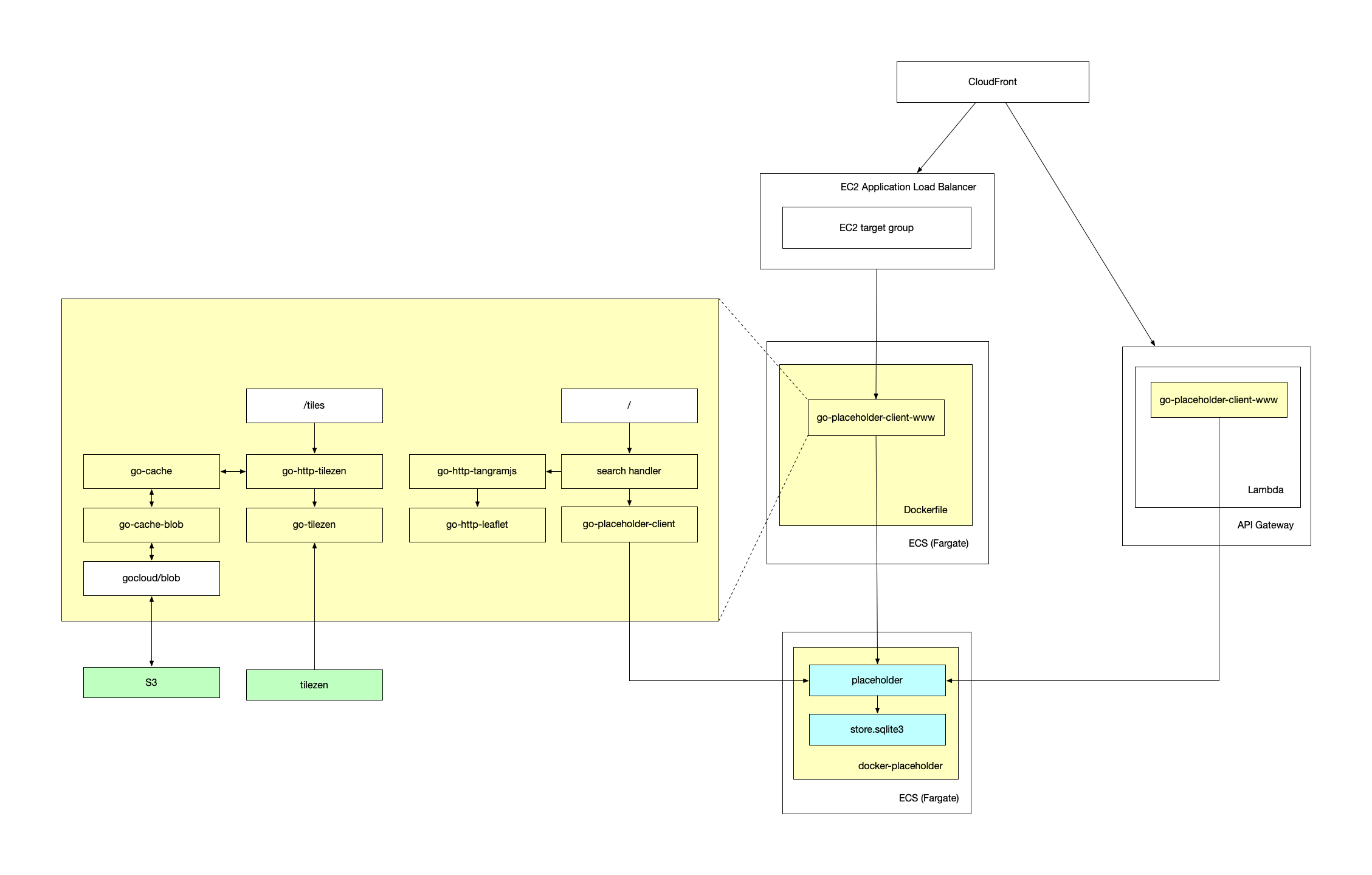
Note: There should be an additional box labeled go-http-bootstrap in the diagram above but you can still get a sense of the many different pieces of functionality all interacting with one another to produce a “simple” web application.
This setup runs the server as a long-running process in an ECS (Fargate) container, fronted by a CloudFront distribution. This means there are no problems involving response encodings and the “bundled” scene files can be loaded and rendered by Tangram without any issues.
The problem with this approach is that in order to fetch Nextzen tiles from their source (out there on the internet) and cache them to an S3 bucket (internally on the AWS network) you need to enable some non-trivial AWS networking configurations. It’s possible but it requires a lot of button-pressing and I just haven’t figured it all out yet.
There are good reasons why this scenario is more complicated than you might think it needs to be. Networking is a complicated beast, especially so in the age of actively bad actors that we are living through, so I would prefer that AWS be more conservative than not about these things. At the same it’s also a good example of the truism that in order to do simple things in ☁️ the cloud ☁️ it usually involves signing up for two or three more ☁️ cloud ☁️ services.
That’s as far as we’ve gotten to date. Our Placeholder endpoint isn’t available for use by the general public, at least not yet, but we have made all of the software available on GitHub for you to set up your own instance. We’ve already identified a series of outstanding UI and UX issues so if you’d like to lend a hand that would be a good place to start.

This post started by saying that it is “now easy, possible and inexpensive to install and operate a coarse geocoding service, with global coverage, support for multiple languages and stable permanent identifiers using openly licensed data” which is important because all museum collections are ultimately rooted in place. Tools like Placeholder and openly licensed data like Who’s On First make it possible for museums and libraries and archives to adopt a common, yet flexible, notion of place with which all our collections might hold hands.